A comparison of distributed machine learning platform
A short summary and comparison of different platforms. Based on this blog and (Zhang et al., 2017).
We categorize the distributed ML platforms under 3 basic design approaches:
- basic dataflow
- parameter-server model
- advanced dataflow.
We talk about each approach in brief:
- using Apache Spark as an example of the basic dataflow approach
- PMLS (Petuum) as an example of the parameter-server model
- TensorFlow and MXNet as examples of the advanced dataflow model.
Spark
Spark enables in-memory caching of frequently used data and avoids the overhead of writing a lot of intermediate data to disk. For this Spark leverages on Resilient Distributed Datasets (RDD), read-only, partitioned collection of records distributed across a set of machines. RDDs are the collection of objects divided into logical partitions that are stored and processed as in-memory, with shuffle/overflow to disk.
In Spark, a computation is modeled as a directed acyclic graph (DAG), where each vertex denotes an RDD and each edge denotes an operation on RDD. On a DAG, an edge E from vertex A to vertex B implies that RDD B is a result of performing operation E on RDD A. There are two kinds of operations: transformations and actions. A transformation (e.g., map, filter, join) performs an operation on an RDD and produces a new RDD.
A typical Spark job performs a couple of transformations on a sequence of RDDs and then applies an action to the latest RDD in the lineage of the whole computation. A Spark application runs multiple jobs in sequence or in parallel.
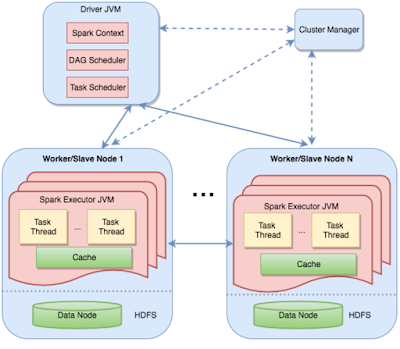
A Spark cluster comprises of a master and multiple workers. A master is responsible for negotiating resource requests made by the Spark driver program corresponding to the submitted Spark application. Worker processes hold Spark executors (each of which is a JVM instance) that are responsible for executing Spark tasks. The driver contains two scheduler components, the DAG scheduler, and the task scheduler. The DAG scheduler is responsible for stage-oriented scheduling, and the task scheduler is responsible for submitting tasks produced by the DAG scheduler to the Spark executors.
The Spark user models the computation as a DAG which transforms & runs actions on RDDs. The DAG is compiled into stages. Unlike the MapReduce framework that consists of only two computational stages, map and reduce, a Spark job may consist of a DAG of multiple stages. The stages are run in topological order. A stage contains a set of independent tasks which perform computation on partitions of RDDs. These tasks can be executed either in parallel or as pipelined.
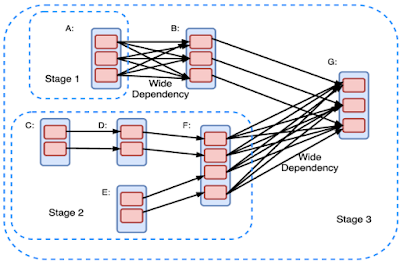
Spark defines two types of dependency relation that can capture data dependency among a set of RDDs:
- Narrow dependency. Narrow dependency means each partition of the parent RDD is used by at most one partition of the child RDD.
- Shuffle dependency (wide dependency). Wide dependency means multiple child partitions of RDD may depend on a single parent RDD partition.
Narrow dependencies are good for efficient execution, whereas wide dependencies introduce bottlenecks since they disrupt pipelining and require communication intensive shuffle operations.
Fault tolerance
Spark uses the DAG to track the lineage of operations on RDDs. For shuffle dependency, the intermediate records from one stage are materialized on the machines holding parent partitions. This intermediate data is used for simplifying failure recovery. If a task fails, the task will be retried as long as its stage’s parents are still accessible. If some stages that are required are no longer available, the missing partitions will be re-computed in parallel.
Spark is unable to tolerate a scheduler failure of the driver, but this can be addressed by replicating the metadata of the scheduler. The task scheduler monitors the state of running tasks and retries failed tasks. Sometimes, a slow straggler task may drag the progress of a Spark job.
Machine learning on Spark
Spark was designed for general data processing, and not specifically for machine learning. However, using the MLlib for Spark, it is possible to do ML on Spark. In the basic setup, Spark stores the model parameters in the driver node, and the workers communicate with the driver to update the parameters after each iteration. For large scale deployments, the model parameters may not fit into the driver and would be maintained as an RDD. This introduces a lot of overhead because a new RDD will need to be created in each iteration to hold the updated model parameters. Updating the model involves shuffling data across machines/disks, this limits the scalability of Spark. This is where the basic dataflow model (the DAG) in Spark falls short. Spark does not support iterations needed in ML well.
PMLS
PMLS was designed specifically for ML with a clean slate. It introduced the parameter-server (PS) abstraction for serving the iteration-intensive ML training process.
In PMLS, a worker process/thread is responsible for requesting up to date model parameters and carrying out computation over a partition of data, and a parameter-server thread is responsible for storing and updating model parameters and making response to the request from workers.
Figure below shows the architecture of PMLS.

- The parameter server is implemented as distributed tables. All model parameters are stored via these tables. A PMLS application can register more than one table. These tables are maintained by server threads. Each table consists of multiple rows. Each cell in a row is identified by a column ID and typically stores one parameter. The rows of the tables can be stored across multiple servers on different machines.
- Workers are responsible for performing computation defined by a user on partitioned dataset in each iteration and need to request up to date parameters for its computation. Each worker may contain multiple working threads. There is no communication across workers. Instead, workers only communicate with servers.
- '’worker’’ and ‘‘server’’ are not necessarily separated physically. In fact server threads co-locate with the worker processes/threads in PMLS.
Error tolerance of ML algorithm.
PMLS exploits the error-tolerant property of many machine learning algorithms to make a trade-off between efficiency and consistency.
In order to leverage such error-tolerant property, PMLS follows Staleness Synchronous Parallel (SSP) model. In SSP model, worker threads can proceed without waiting for slow threads.
Fast threads may carry out computation using stale model parameters. Performing computation on stale version of model parameter does cause errors, however these errors are bounded.
The communication protocol between workers and servers can guarantee that the model parameters that a working thread reads from its local cache is of bounded staleness.
Fault tolerance
Fault tolerance in PMLS is achieved by checkpointing the model parameters in the parameter server periodically. To resume from a failure, the whole system restarts from the last checkpoint.
Programing interface
PMLS is written in C++.
While PMLS has very little overhead, on the negative side, the users of PMLS need to know how to handle computation using relatively low-level APIs.
TensorFlow
Tensorflow is the first generation distributed parameter-server system. In TensorFlow the computation is abstracted and represented by a directed graph. But unlike traditional dataflow systems, TensorFlow allows nodes to represent computations that own or update mutable state.
- Variable: a stateful operations, owns mutable buffer, and can be used to store model parameters that need to be updated at each iteration.
- Node: represents operations, and some operations are control flow operations.
- Tensors: values that flow along the directed edges in the TensorFlow graph, with arbitrary dimensionality matrices.
- An operation can take in one or more tensors and produce a result tensor.
- Edge: special edges called control dependencies can be added into TensorFlow’s dataflow graph with no data flowing along such edges.
In summary, TensorFlow is a dataflow system that offers mutable state and allows cyclic computation graph, and as such enables training a machine learning algorithm with parameter-server model.
Architecture
The Tensorflow runtime consists of three main components: client, master, worker.
- client: is responsible for holding a session where a user can define computational graph to run. When a client requests the evaluation of a Tensorflow graph via a session object, the request is sent to master service.
- master: schedules the job over one or more workers and coordinates the execution of the computational graph.
- worker: Each worker handles requests from the master and schedules the execution of the kernels (The implementation of an operation on a particular device is called a kernel) in the computational graph. The dataflow executor in a worker dispatches the kernels to local devices and runs the kernels in parallel when possible.
Characteristics
Node Placement
If multiple devices are involved in computation, a procedure called node placement is executed in a Tensorflow runtime. Tensorflow uses a cost model to estimate the cost of executing an operation on all available devices (such as CPUs and GPUs) and assigns an operation to a suitable device to execute, subject to implicit or explicit device constraints in the graph.
Sub-graph execution
TensorFlow supports sub-graph execution. A single round of executing a graph/sub-graph is called a step.
A training application contains two type of jobs: parameter server (ps) job and worker job. Like data parallelism in PMLS, TensorFlow’s data parallelism training involves multiple tasks in a worker job training the same model on different minibatches of data, updating shared parameters hosted in a one or more tasks in a ps job.
A typical replicated training structure: between-graph replication

There is a separate client for each worker task, typically in the same process as the worker task. Each client builds a similar graph containing the parameters (pinned to ps) and a single copy of the compute-intensive part of the computational graph that is pinned to the local task in the worker job.
For example, a compute-intensive part is to compute gradient during each iteration of stochastic gradient descent algorithm.
Users can also specify the consistency model in the betweengraph replicated training as either synchronous training or asynchronous training:
- In asynchronous mode, each replica of the graph has an independent training loop that executes without coordination.
- In synchronous mode, all of the replicas read the same values for the current parameters, compute gradients in parallel, and then apply them to a stateful accumulators which act as barriers for updating variables.
Fault tolerance
TensorFlow provides user-controllable checkpointing for fault tolerance via primitive operations: save writes tensors to checkpoint file, and restore reads tensors from a checkpointing file. TensorFlow allows customized fault tolerance mechanism through its primitive operations, which provides users the ability to make a balance between reliability and checkpointing overhead.
MXNET
Similar to TensorFlow, MXNet is a dataflow system that allows cyclic computation graphs with mutable states, and supports training with parameter server model. Similar to TensorFlow, MXNet provides good support for data-parallelism on multiple CPU/GPU, and also allows model-parallelism to be implemented. MXNet allows both synchronous and asynchronous training.
Characteristics
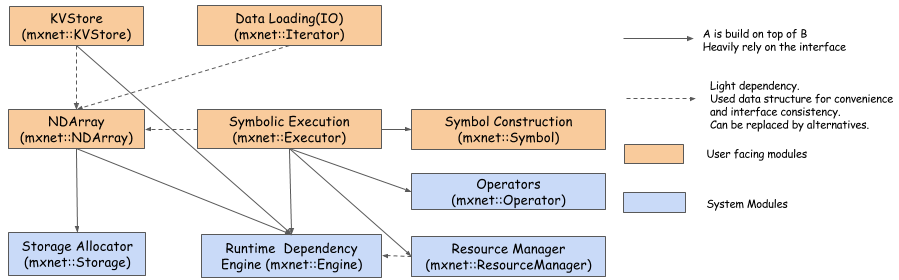
Figure below illustrates main components of MXNet. The runtime dependency engine analyzes the dependencies in computation processes and parallelizes the computations that are not dependent. On top of runtime dependency engine, MXNet has a middle layer for graph and memory optimization.
Fault tolerance
MXNet supports basic fault tolerance through checkpointing, and provides save and load model operations. The save operaton writes the model parameters to the checkpoint file and the load operation reads model parameters from the checkpoint file.
Reference
- Zhang, Kuo and Alqahtani, Salem and Demirbas, Murat, ‘A Comparison of Distributed Machine Learning Platforms’, ICCCN, 2017. The post is used for study purpose only.
